
Mathematical Ability and AI
Are current AIs better at math than 99.99% of humans?

LLMs are shockingly good at math
The last year or so has seen a dramatic improvement in the capabilities of generative AI systems based on Large Language Models (LLMs). Much of this is due to “reasoning” or “thinking” models, which have become astoundingly good at mathematical and programming tasks. Nowhere is this clearer than in the realm of competitive math and programming, where the tasks are clearly defined and self-contained.
If you haven’t been following closely, you could be forgiven for thinking that the idea of LLMs being good a math is ludicrous. But in fact, mathematics might very well be the intellectual task that they are best at. Not only do top LLMs exceed the capabilities of the median human on math competitions; they exceed the capabilities of at least 99.9% of humans, and arguably even more.
Let’s look at some context. Thanks to the folks at MathArena, we have comparisons of the performance of many LLM models on some of the premier math competitions in the United States (and the world).
On the 2025 version of the AIME, a competition taken each year by top American high school students, the best model manages to solve every problem in at least one of four attempts, and all but three of the thirty problems (there are two versions of the exam, each with fifteen problems) on all four attempts. It’s possible that this was due to training contamination (because the model released after the exam), but o3-mini, which released before the exam, solved all but two problems on at least one attempt, and twenty-two of the thirty problems on every attempt.
How does this compare to humans? In the three-hour exam, fewer than 100 students (probably around 60, but the contest organizers don’t seem to provide exact statistics) in the country solve at least 13 out of the 15 problems, and about three hundred solve at least 11. (I was actually surprised at this level of performance; twenty years ago a score of 13 would have put you in the top twenty, and a score of 11 in the top sixty. People are much better at this exam than they used to be.) With about 16 million high school students in the US, the lower of these represents a performance of 2 in one hundred thousand (better than 99.998%).
But this is just one type of problem. What about proofs? On the 2025 International Mathematical Olympiad (the IMO is given annually to about 600 students in the world — up to 6 from each country are allowed), the top consumer LLM (the highest power version of GPT-5) scores an average of 16 points out of 42, a score high enough to rank near the median participant. In the realm of models not available to consumers, both OpenAI and Google Deepmind reported LLMs fully solving 5 of the 6 problems1; enough to earn a “gold medal” (which 72 students did).
Now, the mathematics used in the AIME and Olympiads, while difficult, is somewhat narrow, and the problems are expected to be solved, without references, by students in the matter of minutes or hours. Project Euler, while not primarily a competition, has a somewhat different approach. The problems typically require both mathematical insight and programming to complete, and while the answers are numerical, they are very rarely guessable. They also cover a very wide range of topics and a very wide range of difficulties (the easiest new-release problems are around the level of a moderately difficult AIME problem; the hardest ones are more difficult than the hardest International Math Olympiad problems, sometimes garnering fewer than ten solutions worldwide within twenty-four hours).
Also, Project Euler solutions — unlike AIME and Math Olympiad solutions — are not available on the public internet. Some individuals leak numerical answers, but usually not right away, and these typically provide little clue to the solution, so inspecting the reasoning output it is easy to verify whether the AI solutions are just finding and regurgitating the leaked answers. They aren’t. Also, one can run the LLM with internet search disabled.
MathArena has also been running LLMs on the latest Project Euler problems (with code execution tooling enabled, since this is generally needed for computing the answer). The results are astounding. As of this writing, the top LLM solves (at least one out of four times, which is good enough for a human as well since answers can be submitted multiple times until the correct one is found) 14 of the most recent 22 problems.
Does all this mean that these AIs are better at math than 99.99% (or more) of humans? That’s a complicated question, and I’m not sure than a yes-or-no response would mean much. Mathematical skill is highly multifaceted. The short version of my answer is that these AIs seem to be enormously better at some of these facets than essentially all humans, and that their astounding performance is the result of leaning on these strengths to substitute for the other factors that contribute to the best humans’ mathematical skill.
For the long version, we’ll look a little more in depth at what those facets of mathematical ability are, and at how competition problems are solved.
Facets of Mathematical Skill
We can divide mathematical skills into a few categories. Different people’s divisions will be different, and the skills are not independent of each other. The following is just one way of trying to break “mathematical ability” down, and while I think most mathematicians would agree that all of these are important, this particular enumeration is just my stab at it, not a canonical list.
1. Attention to detail: the ability to avoid elementary errors when doing mathematics, whether in executing algorithms, constructing chains of logic, or otherwise.
2. Fluency: comfort with the basic algorithms and notations of mathematics, and ability to use them easily when appropriate.
3. Processing speed: simply how quickly one can think.
4. Background Knowledge: how much one knows about existing theorems, techniques, and so on, within the relevant areas of mathematics.
5. Logical Thinking: the ability to construct a clear and rigorous line of thought.
6. Problem Decomposition and Transformation: the ability to productively split apart a problem into parts, find appropriate generalizations, or reinterpret and transform a problem to make it easier.
7. Creative Association: the ability to make insightful associations between the problem at hand and other mathematical ideas with which it shares features, and which therefore might be helpful in its solution.
8. Mathematical Intuition: the ability to see which strategies and approaches are likely to be fruitful, and which ones are likely to lead to dead ends; and the ability to guess what sorts of results are likely to be true.
There is, of course, a lot of mutual interdependence here: it’s hard to make creative associations without the requisite background knowledge. But the key thing is that human problem-solvers make use of all of these, in varying proportions, to solve challenging problems.
Substitution
It can be misleading to gauge mathematical intelligence by the ability to solve problems, because these skills can be substituted for each other in ways that undermine what you are trying to measure. One obvious example of this is when someone has seen the same problem before, and can reproduce the solution from memory; you may think that you are testing logical thinking, problem decomposition, and mathematical intuition, but you are really just seeing a particular bit of background knowledge. But this kind of substitution extends beyond simply having seen the exact problem before, and to more general things like knowledge of techniques.
A particularly well-known and instructive example is Problem 6 (the hardest problem) from the 1988 IMO:
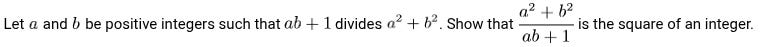
This problem is legendary in competitive mathematics circles. Arthur Engel (in Problem-Solving Strategies) has this to say about it:
Nobody of the six members of the Australian problem committee could solve it. Two of the members were Georges Szekeres and his wife, both famous problem solvers and problem creators. Since it was a number theoretic problem it was sent to the four most renowned Australian number theorists. They were asked to work on it for six hours. None of them could solve it in this time. The problem committee submitted it to the jury of the XXIX IMO marked with a double asterisk, which meant a superhard problem, possibly too hard to pose. After a long discussion, the jury finally had the courage to choose it as the last problem of the competition. Eleven students gave perfect solutions.
But anyone who has trained for math Olympiads in the last three decades would find the problem easy. The canonical solution uses a trick now known as “Vieta jumping” or “root flipping”. If you’ve seen the technique before, even if you haven’t seen this particular problem, the application is not hard to find, and the problem can be solved and proof written in about 15 minutes. What once was a problem that required incredible creativity and mathematical intuition can now be solved by many more people, because most competitors now have the appropriate background knowledge.
Another example of substitution by human competitors is the use of Muirhead’s inequality. I’ll spare you the details, but it used to be the case that many symmetric inequality problems on Olympiads, which generally had elegant and creative intended solutions, could be “bashed” by the use of this fairly general inequality — provided you were very good at doing a lot of algebra without errors, and had the time and/or speed to write down what was often an extremely long proof. Eventually enough competitors were doing this that problem writers stopped using problems that could be solved this way.
Substitution by AI
I don’t have any special insight into the true inner workings of LLMs when they solve these problems. But based on some general principles, and on reading a number of AI solutions to recent Project Euler problems and comparing them to how I and other humans solved the problems, I’ve come to the conclusion that the LLMs are probably so successful because they manage to leverage superhuman Background Knowledge and Processing Speed, as well as very strong ability in something which I might describe as a subset of Creative Association.
The fact that an AI, trained on a corpus including almost all published mathematics and using a huge amount of computing power, would have superhuman background knowledge and processing speed is unsurprising. The skill at creative association is probably (but take this with a grain of salt) the result of a combination of the background knowledge and the way that an LLM operates on a language level; related topics share language structure and vocabulary, and so are likely to be productively juxtaposed by the LLM. (It is also enhanced by processing speed: a computer can simply try far more combinations until it finds one that fits.)
One can see this cash out in a few ways in LLM solutions to these problems. Some solutions are similar to human ones because there is something “obvious” (to an experienced problem-solver) to do, on account of the correct methods to use being similar to ones in similar problems. But on harder problems, the LLM solutions often differ from human ones in two ways.
One is that they tend to “bash” at the problem with theorems or formulas rather than take a step back and look for insight in a way that requires a sort of intuition that’s not easily encapsulated by verbally or algebraically stated theorems. For instance, see this article, which says this about the frontier AI’s solution to IMO 2025 Problem 1:
I think what’s going on here is that the LLMs cannot use anything like human spatial intuition to see that removing or adding a side line results in a similar triangle, so they have to use a more symbolic approach to reach the same conclusion.
The other is that LLM solutions tend to be very machinery-heavy. Where human solutions will usually do ad-hoc analysis of a particular problem, LLM solutions often seem to immediately reach for high level theories and powerful, general results — the proverbial swatting of a fly with a sledgehammer. When this succeeds, it produces solutions that look incredibly sophisticated.
So we see LLM solutions that mysteriously find just the right result in the literature to apply to a problem, or bash at it with step-by-step algebra, or invoke high-level mathematical machinery, or just do “the obvious thing” repeatedly until all parts of the problem are solved. But when these don’t work, and a creative, ad-hoc strategy is needed (even if the strategy isn’t very difficult), the LLM often just fails to solve the problem.
This model of LLM success at competition math is admittedly speculative on my part. However, I’m somewhat more confident in it because I was able to use it to make a prediction. Shortly after GPT-5 released and it was proving to be surprisingly capable of solving easy and medium level Project Euler problems, I guessed that it would also be able to solve a particular problem which was exceptionally difficult for humans, but which has characteristics that make it especially weighted towards background knowledge and the particular kind of creative association at which LLMs excel. (Unfortunately I won’t say which one here, or exactly why I thought an LLM solution was likely, as I don’t want to spoil anything for humans reading this piece who may want to solve the problem in question themselves.) Someone with access to the most powerful version of GPT-5 (I don’t pay for it) was able to make the attempt for me. The LLM succeeded.
So are frontier AIs actually better at math than 99.99% of the population? In some sense, yes; certainly they can solve well-defined problems at that level. But AI capabilities don’t straightforwardly match up to human ones. Talented humans remain superior to LLMs at creative ad-hoc analysis and at noticing and correcting logical errors, even while an LLM can find and apply needles in the haystack of existing results better than almost all humans.
Bonus: The future of online competitions
I’m motivated to think about these things partly because I think that we’re going to lose some nice things pretty soon. Specifically, I think that unproctored math and programming competitions are under threat of disappearing.
Even if AIs soon outperform even the best humans at competitive math and programming tasks, traditional offline, proctored competitions — like Olympiads — will most likely continue. After all, computers have been better than the top humans at chess for over two decades, and there is still interest in chess and chess tournaments. But I expect that the days of online competitions, which have blossomed in the 21st century, are numbered. Competitive programming is already dealing with a massive AI cheating problem, and Project Euler is facing similar issues (despite not having any prizes or even a formal competition structure). While most community members are honest, it only takes a few cheaters to cause problems, and even the mere possibility of cheating brings the integrity of the competition into question.
It’s possible we’ll see some competitions deal with this by designing problems around the use of AI, by only including problems that are not trivialized by AI use, and expecting competitors to have access to AI while they work. But this is a moving target, as AI capabilities are constantly changing; it removes from play a substantial fraction of desirable problems; and it goes against the ethos of environments like Project Euler. It seems likely that the golden age of online math and programming competitions has come to an end.
Project Euler will probably survive, a bit diminished, by abandoning its competitive aspect, as more and more problems become trivialized by consumer AI and policing the leaderboards for cheating becomes untenable. I have no idea what will happen to the many competitive programming platforms. And USAMTS (not an online competition, but unproctored and untimed, and recently a gateway to AIME and USAMO) is probably going to face a cheating problem far more massive than it already has, and may need to be abandoned.
It’s been pointed out that this performance is not an enormous gain for AI in general over last year. Previously, AI packages using an LLM in combination with specially trained proof generation/evaluation tools could achieve similar results; the big leap here is in LLM capabilities specifically.